
head: 数据库头文件. |
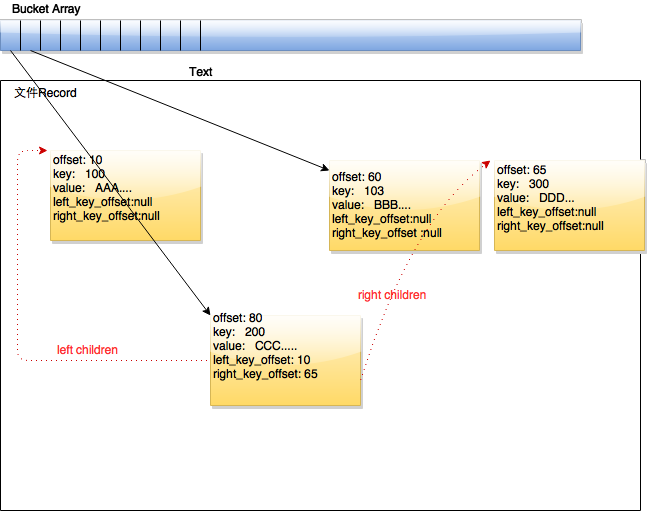
hash数据库的原理是通过key值用一个hash算法算出一个bidx值,然后在这个表(bucket array)里查这个bidx对应的
key-value值在文件中的偏移,再在文件中查找record记录.
当然hash算法是会冲突的,当不同的key值算到了同样的hash,那我们仅用上面的一个bucket array是不能区分的,
Tokyo Cabinet采用一个二叉树来管理冲突的key, hash相等的所有记录都是互相用数据单元的left,right指针
(其实就是一个offset值)连接起来的
如下图 :
转载请注明出处,谢谢。。